


Rather beautiful and ostensive graphs, don't you think? :)
This was always my weakness — representing dull statistic numbers in obvious and informative form — and if you share it with me, today I will tell you about RRD and rrdtool - rather easy and customizable tools for storing statistic data and building graphs from stored information.
Basic theory - explanation by simple example
RRD (round-robin database) — is a database, which has costant size and constant quantity of records. All the records in RRD are stored cyclically. What does it mean?
Let's imagine that you want to store results of pinging host for last 24 hours, in miliseconds. Ping command is executed every 5 minutes, so the result will be written to database every 300 seconds. A little math:
(60*60*24) / 300 = 288
This means that our database will have constant quantity of 288 rows. After the first 288 records old records, starting from the first one, will be deleted, and new ones will be added to the end of database.
Now let's complicate our task a bit. We want to save ping results for the last month. Ping command is executed every 5 minutes (300 seconds), but we don't need such an accuracy for month's statistics, so we can setup our database to insert records every hour. This means, that our database will store in cache 12 values for the last 60 minutes and will add to database one of the values: AVERAGE, MINIMUM, MAXIMUM or LAST, this depends on configuration of database.
(60*60*24*31) / 300 / 12 = 744
So, we will need 744 rows to store ping statistics per month.
Explanation in RRD "language"
First of all - rrd database must have at least one Data Source (DS). This is the structure of DS:
DS:variable_name:DST:heartbeat:min:max
- variable_name — a name for variable that will be used to access data from database.
-
DST (Data Source Type) can be one of the next variants
- COUNTER — saves the rate of change; best to save data that allways increases (amount of traffic, and so on);
- DERIVE — same as COUNTER, but allows negative rates;
- ABSOLUTE - saves the rate of change, but it assumes that the previous value is set to 0; it is good if we want to count events after the last data input;
- GAUGE — saves the values itself, not the rate; best for storing monitoring data — CPU load, memory usage, ping miliseconds, and so on.
- heartbeat — time between two data inputs, in seconds.
- min and max — minimal and maximal values for input data.
So, accordingly to our example, DS will look this way:
DS:ping_ms:GAUGE:300:0:100000
Variable name is 'ping_ms', Data Source Type is GAUGE, and heartbeat is set to 300 seconds, because we execute ping command every 300 seconds. Minimal value is 0, and maximun value is set to 100000.
Also RRD must include at least one Round-robin Archive (RRA). RRA's structure:
RRA:CF:xff:step:rows
Input data comes to database through DS every 300 seconds. step parameter sets how many values of input data should be in cache before a Consolidation Function (CF) could be applied to them. rows parameter sets how many values will contain this RRA.
Let's get back to our example.
Our RRD will include 2 RRA — for last 24 hours and last 31 day. So, here is the first RRA:
RRA:AVERAGE:0.5:1:288
This means, that our first archive, which will store data for last 24 hours, will consist of 288 rows and every new value will be added to database immediately. CF can be ignored in this case, because no values will be placed in cache.
Second RRA:
RRA:AVERAGE:0.5:12:744
This archive will store info for last 31 day and will contain 744 rows. Every new value will be placed in cache. Then amount of values in cache reaches 12, CF will be applied to them. In our case CF is AVERAGE, which means that arithmetic average of values in cache will be inserted in database. Other possible CFs are:
- MINIMUM — minimum value in cache;
- MAXIMUM — maximum value in cache;
- LAST — last value in cache.
In addition, if we are talking about our example, the host we are pinging can be unreachable for some time. In this case the input data will be a special RRD type called UNKNOWN. xff — is a float parameter, from 0 to 1, which sets the maximum percentage of UNKNOWN values in cache, at which the applying of CF is allowed. For our second
RRA xff is set to 0.5, which means that CF will be applied only if amount of UNKNOWN values in cache is less or equal 6. xff for first RRA can be ignored.
Drawing techniques
After we have updated our RRD with some data we can easily create graphs based on data, fetched from RRD. All the practical steps are described in section below, but there are several points that you have to understand before we can create graphs:
- Time period, that will be represented in graph, must be defined;
-
We must define default variable, which will be the source of data from our RRD database. In our case it is all values of ping_ms variable in RRA archive, which will be chosen automatically accordingly to a defined period of time. Here is the syntax for default variable:
DEF:<default_variable_name>=<rrd_database_file>:<name_of_variable_in_rrd>:<consolidation_function>For example:DEF:ping_host=ping.rrd:ping_ms:AVERAGE
-
We can add more variables, based on default variable, and apply some math to them. All the additional calculations must be written as Reverse Polish Notation (RPN). There are two types of additional variables, that we can create:
-
VDEF: consolidation function will be applied to all values in RRA. It's syntax:
VDEF:<variable_name>=<default_variable_name>,<condolidation_function>For example:VDEF:ping_average=ping_host,AVERAGE
-
CDEF: some calculation will be applied to all values in RRA. The calculation must be written as RPN expression. CDEF's syntax:
CDEF:<variable_name>=<rpn_expression>For example - if ping_host is greater then ping_average , the value will be assigned to ping_over_average:CDEF:ping_over_average=ping_host,ping_average,GT,ping_host,0,IF
-
VDEF: consolidation function will be applied to all values in RRA. It's syntax:
- Every defined variable will be shown on a graph as a graphical element. There are 5 types of graphical elements: AREA, LINE1, LINE2, LINE3(number stands for width) and STACK. Please see the example below to understand how the variables must be connected with graphical elements.
Creating and updating database. Simple graph
Now, after some theory, let's try some practice. The main tool for working with RRD database is command-line utility rrdtool. There are modules for different languages(Perl, Python), but on closer inspection it becomes apparent that they are wrappers around rrdtool, so rrdtool is a must dependency for any RRD-module.
Let's create RRD database file, using Data Source and Round-Robin Archives from the example above. As I've already mentioned - one additional parameter is needed for creating RRD - initial start time, in unix timestamp format:
$ rrdtool create ping.rrd \ --start 1386350100 \ DS:ping_ms:GAUGE:300:0:100000 \ RRA:AVERAGE:0.5:1:288 \ RRA:AVERAGE:0.5:12:744
Several cheks, for peace of mind =):
$ file ping.rrd ping.rrd: RRDTool DB version 0003 $ rrdtool info ping.rrd filename = "ping.rrd" rrd_version = "0003" step = 300 last_update = 1386350100 ds[ping_ms].type = "GAUGE" ds[ping_ms].minimal_heartbeat = 300 ds[ping_ms].min = 0.0000000000e+00 ds[ping_ms].max = 1.0000000000e+05 ds[ping_ms].last_ds = "UNKN" ds[ping_ms].value = 0.0000000000e+00 ds[ping_ms].unknown_sec = 200 rra[0].cf = "AVERAGE" rra[0].rows = 288 rra[0].pdp_per_row = 1 rra[0].xff = 5.0000000000e-01 rra[0].cdp_prep[0].value = NaN rra[0].cdp_prep[0].unknown_datapoints = 0 rra[1].cf = "AVERAGE" rra[1].rows = 744 rra[1].pdp_per_row = 12 rra[1].xff = 5.0000000000e-01 rra[1].cdp_prep[0].value = NaN rra[1].cdp_prep[0].unknown_datapoints = 2
Now lets put some fake data in our RRD. $RANDOM - is a built-in bash variable(also available in ksh): each reference of this variable generates random integer number from 0 to 32767:
$ start_time="1386350100"
$ heartbeat="300"
$ for i in {1..20} \
do \
shift_time=$((heartbeat*i)) \
input_time=$((start_time+shift_time)) \
rrdtool update ping.rrd $input_time:$RANDOM \
done
And fetch data from database, to be sure that data has arrived from Data Source:
$ last_shift=$((300*10))
$ rrdtool fetch ping.rrd AVERAGE \
--start $start_time --end $((start_time+last_shift))
ping_ms
1386350400: 1.2571000000e+04
1386350700: 1.7505000000e+04
1386351000: 5.7370000000e+03
1386351300: 1.9321000000e+04
1386351600: 6.6680000000e+03
1386351900: 2.8170000000e+04
1386352200: 3.1665000000e+04
1386352500: 1.0403000000e+04
1386352800: 3.8130000000e+03
1386353100: 5.5630000000e+03
1386353400: 5.3420000000e+03
Now the most interesting part - let's build graph from the values in RRD:
$ last_shift=$((300*20)) $ rrdtool graph ping_graph.png \ --start $start_time --end $((start_time+last_shift)) \ DEF:ping_host=ping.rrd:ping_ms:AVERAGE \ VDEF:ping_average=ping_host,AVERAGE \ CDEF:ping_over_average=ping_host,ping_average,GT,ping_host,0,IF \ CDEF:ping_below_average=ping_host,ping_average,LT,ping_host,0,IF \ AREA:ping_over_average#FF0000:"ping over average" \ AREA:ping_below_average#00FF00:"ping below average" \ LINE1:ping_host#222222 \ LINE2:ping_average#FFFF00:"average time of ping" 481x168 $ file ping_graph.png ping_graph.png: PNG image data, 481 x 154, 8-bit/color RGBA, non-interlaced
To make things clear:
- output file for graph is image in PNG format;
- time period is creation time of RRD database + last_shift, which is egual to 300s * 20;
- default variable - is ping_ms for RRA archive, which suits the best for defined time period;
- VDEF variable, ping_average, is constant - it is the arithmetic average of all ping_ms values in RRA archive;
- first CDEF variable is ping_over_average - all the values which are greater then ping_average;
- second CDEF variable is ping_below_average - all the values which are less then ping_average;
- first graphical element: area, red colour - all the ping_over_average values, legend for graph is "ping over average";
- second graphical element: area, green colour - all the ping_below_average values, legend for graph is "ping below average";
- third graphical element: line, 1px width, dark grey colour - all the values of default variable;
- fourth graphical element: line, 2px width, yellow colour - horizontal line with constant value of ping_average, legend is "average time of ping".
And the graph itself:

Easy, isn't it?
Complicated example — sar statistics, pyrrd
sar
sar — is a Unix tool for storing system activity reports. By default sar scripts, which gather information about system (CPU load, memory usage, i/o activity, etc), are launched via cron every 5 minutes and store statistic data in binary files. Here is an example output from sar file for the 17th day of current month, CPU load:
# sar -f /var/log/sa/sa17 ... 12:00:01 AM CPU %user %nice 12:05:01 AM all 0.24 0.00 12:10:01 AM all 0.25 0.00 12:15:01 AM all 0.25 0.00 ... ...
And memory usage:
# sar -f /var/log/sa/sa17 -r ... 12:00:01 AM kbmemfree kbmemused %memused kbbuffers 12:05:01 AM 11485772 4945420 30.10 325736 12:10:01 AM 11484664 4946528 30.10 325736 12:15:01 AM 11485508 4945684 30.10 325736 ... ...
Output of sar utility is just perfect to to be used as a source for RRD.
If you are using CentOS or RHEL, sar can be installed via yum; it is a part of sysstat package:
# yum install sysstat
Post-installation scripts will also register jobs in cron, so you
will need at least 1 hour after installation to get some reasonable
output for RRD.
Setup python virtual environment
virtualenv is a tool, which creates isolated working copy of Python installation. You can work in virtual environments, install additional modules without affecting other Python installations. First of all we need to install python2.6, virtualenv and pip (a manager, which gives access to repository with python modules).
# yum install python26 python26-virtualenv python-pip
After installation we need to create virtual environment itself:
$ virtualenv-2.6 rrd_test New python executable in rrd_test/bin/python2.6 Also creating executable in rrd_test/bin/python Installing setuptools............done.
Now, let's activate new virtual environment:
$ . ./rrd_test/bin/activate (rrd_test)$
Let's check the paths:
(rrd_test)$ which python2.6 ~/temp/rrd_test/bin/python2.6 (rrd_test)$ which pip ~/temp/rrd_test/bin/pip
Everything seems fine, so the next step is to install pyrrd library using pip:
(rrd_test)$ pip install pyrrd Downloading/unpacking pyrrd Downloading PyRRD-0.1.0.tar.gz (454Kb): 454Kb downloaded ... Successfully installed pyrrd Cleaning up...
Python script
I've decided that the best explanation of source code are profuse comments. Below you can see python script, which parses sar output, creates RRD databases, updates them with values from sar output, and draws graph for certain day of month.
I've called it sa2rrd.py. Please save it somewhere in virtual Python environment. Usage example:
(rrd_test)$ python2.6 sa2rrd.py --day <number_of_day>
Output PNG file will be in the directory with script and will look similar to this one:
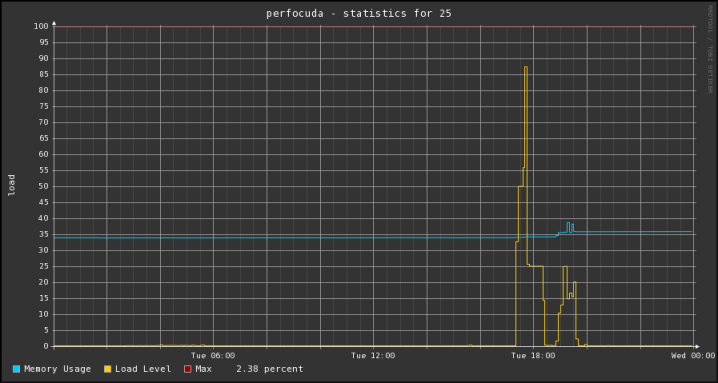
Script's content can be found on pastebin.
Further investigation
If you are interested in the subject of the article - here are several points which may be worth attention:
- rrdcached - daemon, which caches input data. For highload systems;
- RRD-Simple - Perl module to manage RRD databases;
- modifying and customizing graphs accordingly to your needs; please see the documentation;
- RPN - theory, examples;
- more monitoring in Unix-like systems: additional sar parameters, ps, top(htop), iostat, lsof, vmstat, mpstat, netstat, socklist, tcpdump, nmap, ettercap, nagios(by the way - nagios is very friendly to RRD) and many others.

{kind=link}
{kind=link}
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.